My research has been centered around making ML systems adaptable. I have hence explored robustness and trustworthiness in ML systems. This has also evolved into an interest in both NLP and CV towards multimodal reasoning to enhance models.
|
|
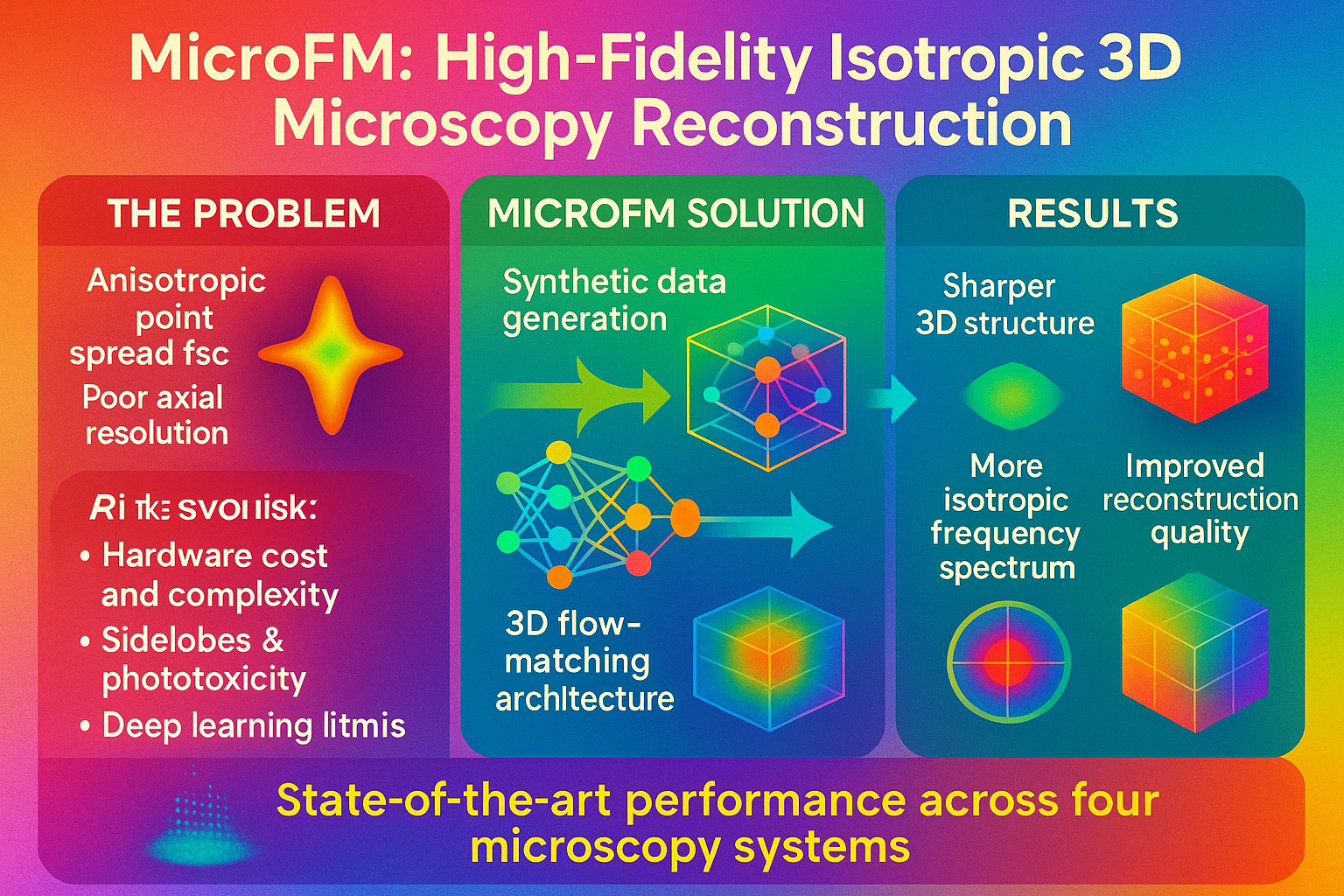
MicroFM: Physics-guided Flow Matching for Isotropic Microscopy Reconstruction
We tackle the challenge of poor axial resolution in microscopy by generating realistic training data using physically accurate PSFs and introducing the first 3D flow-matching framework for reconstruction. Our method, MicroFM, leverages an implicit geometry prior to recover high-fidelity, isotropic volumes across diverse microscopy systems.
Xingzu Zhan,
Runmin Jiang,
Vatsal Gupta,
Tanush Swaminathan,
Yanwen Wang,
Genpei Zhang,
Haili Wang,
Min Xu
Submitted to CVPR 2026
|
|

|
|
|
|
|
|
|
|
|
† and * : Equal Contribution
For a comprehensive and up-to-date list of my publications, please refer to Google Scholar.
Modified template by Jon Barron
Last updated: October 2025
|
| |
